

AI search is reshaping how buyers choose.
When someone asks an LLM, “best CRM for small teams” or “HubSpot vs. Salesforce pricing,” the answer often shapes which vendors make the shortlist and which never get considered at all.
Many LLM citation studies use broad, top-of-funnel prompts. This report isolates bottom-of-funnel (BOFU) prompts — pricing, comparisons, alternatives, and “best for” queries — to understand which sources actually influence decisions when buyers evaluate and choose solutions.
Using citation data from Peec.ai, we analyzed ~1,000 BOFU prompts across major AI platforms to see which domains appear most often in decision-stage answers.
That source mix reveals the real inputs behind AI-driven recommendations.
We break down who AI trusts at the decision stage, why comparison content dominates citations, where brand-owned content loses visibility, and how sourcing behavior shifts across ChatGPT, Perplexity, and Google AI.
This research also reinforces the value of strong Reddit SEO execution in categories where community consensus drives visibility during the decision stage. In many industries, third-party ecosystems now shape AI-driven customer acquisition.
Key Takeaways
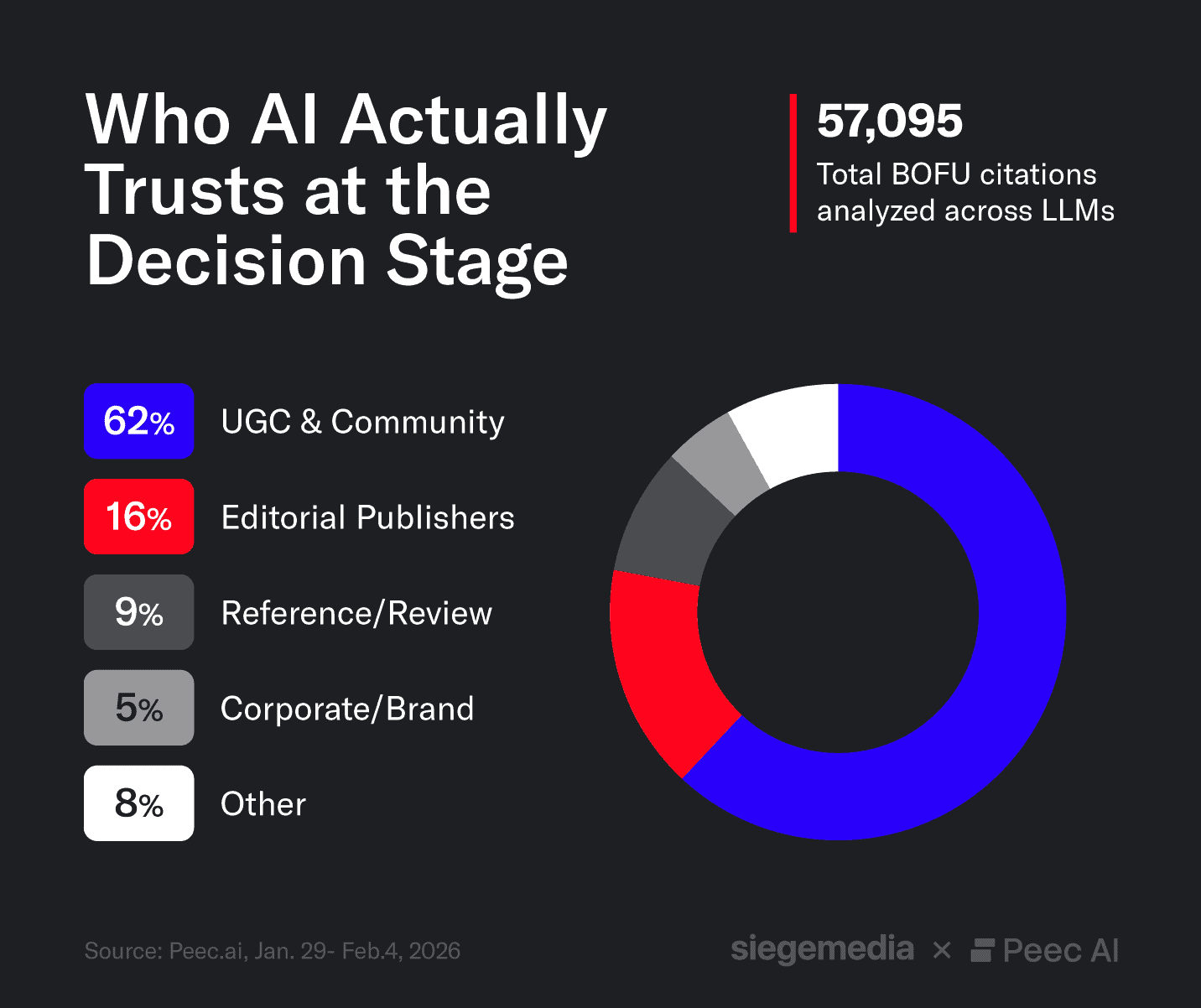
- Reddit dominates AI buying advice. Reddit appears in 62% of bottom-of-funnel LLM responses, making it the most influential source when AI tools recommend products — outpacing all traditional publishers combined.
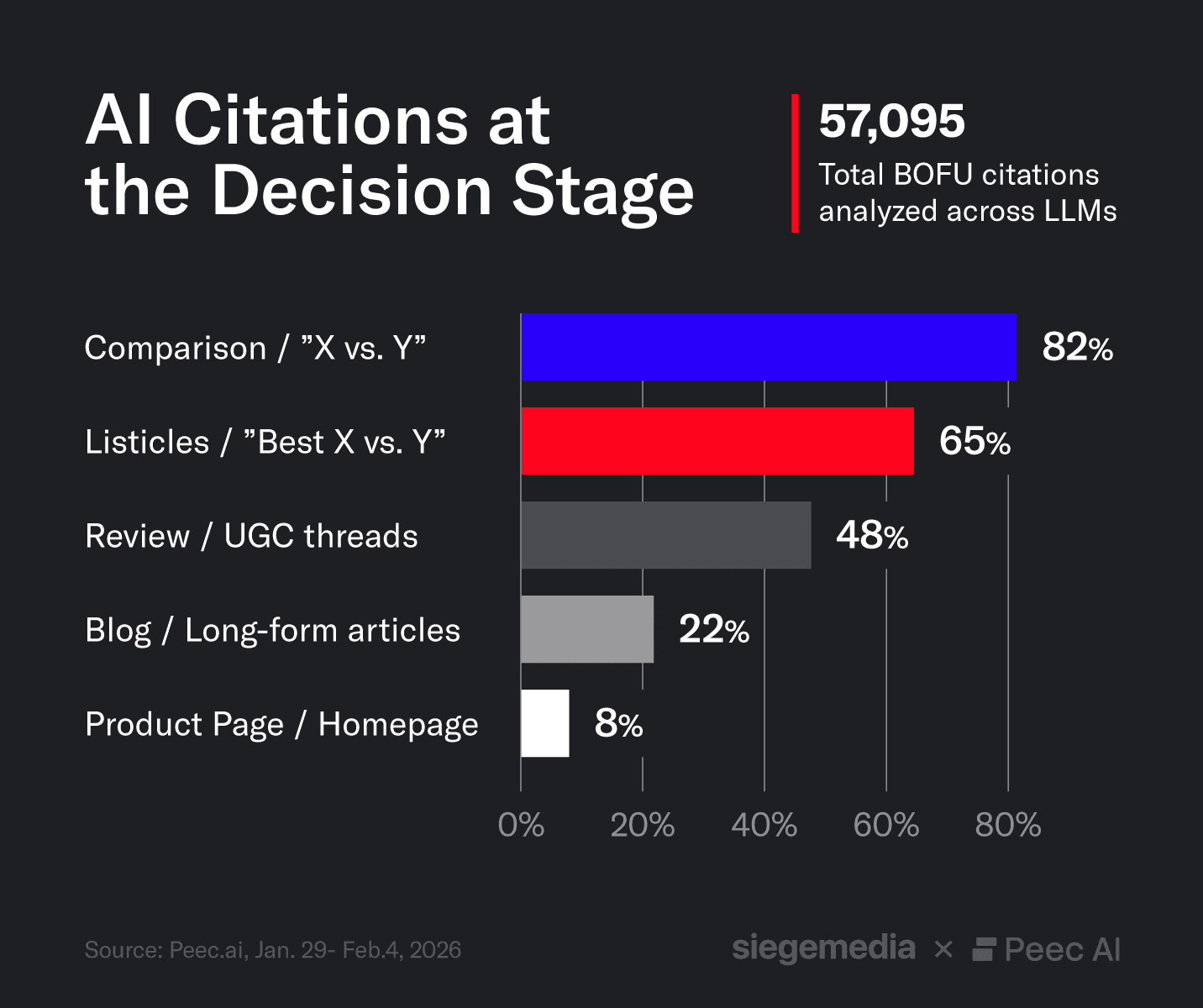
- Comparison content drives AI decisions. “X vs. Y” pages and listicles are the most-cited formats across our study, while product pages and homepages appear in single-digit citation rates.
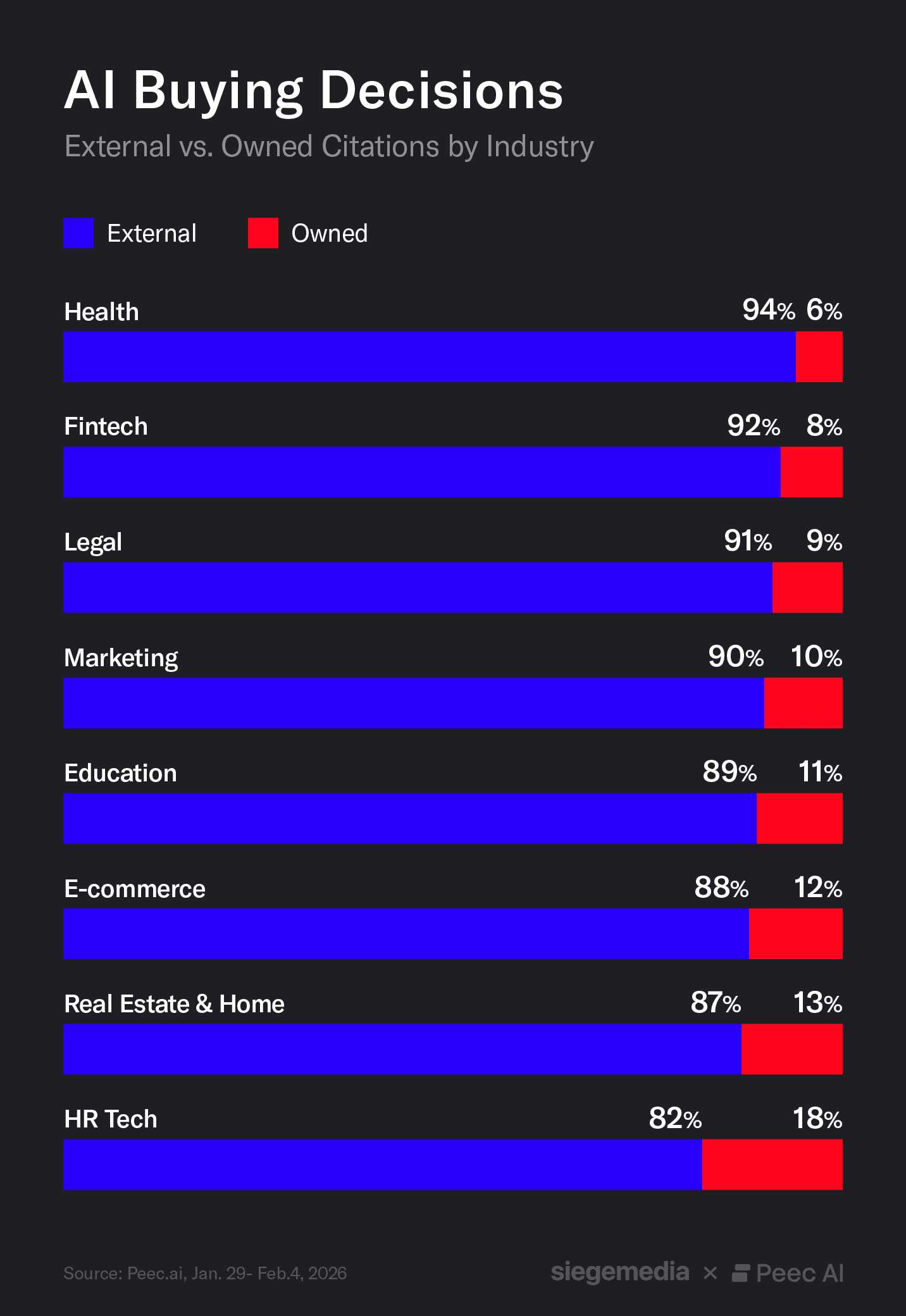
- Brand-owned content rarely shows up at BOFU. Across industries, 80-95% of AI citations come from third-party sources, leaving most brands effectively invisible at the moment of purchase.
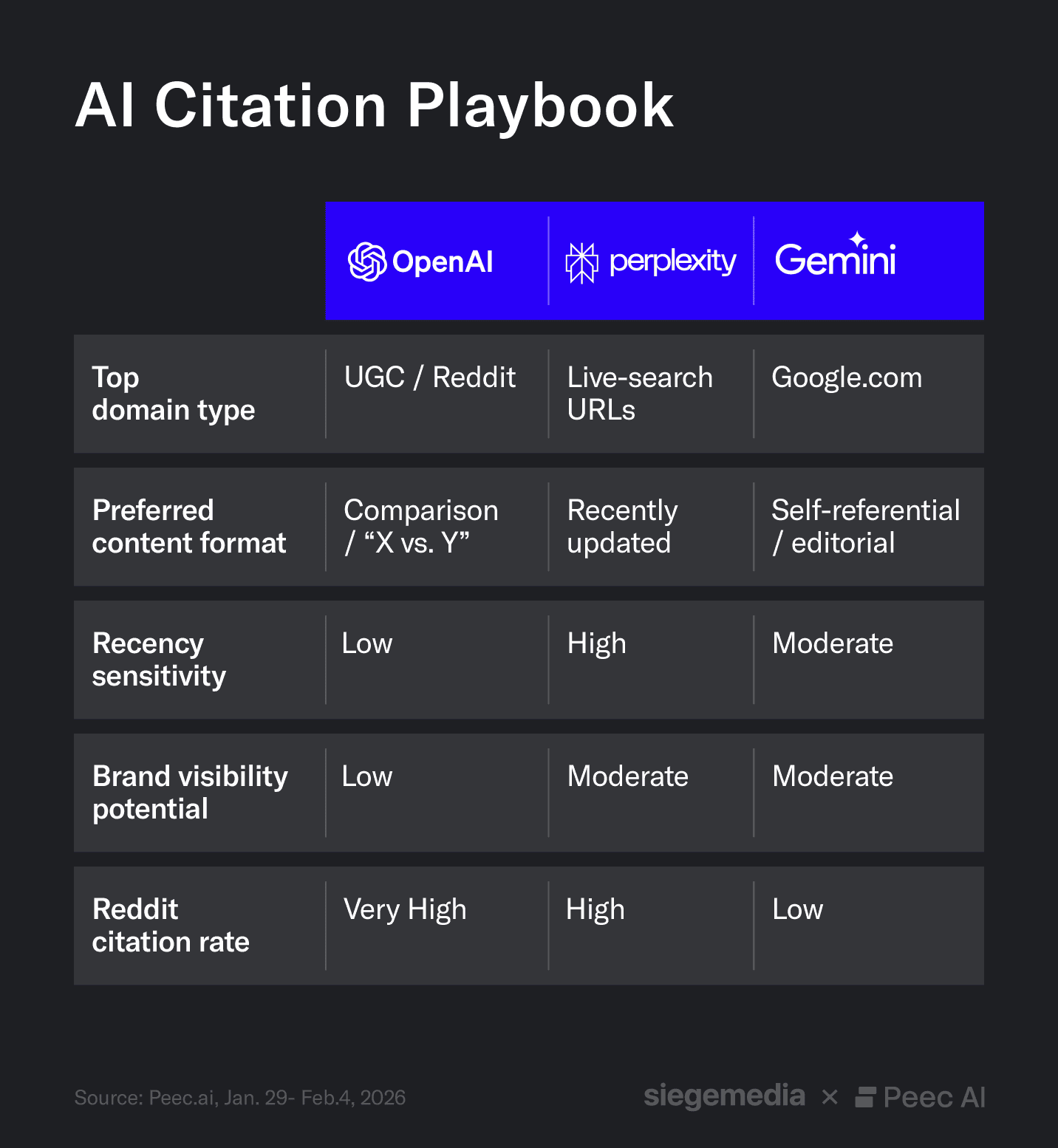
- AI recommendations vary by model. Google AI Overviews lean on Google.com as a meta-source, while ChatGPT and Perplexity prioritize UGC and comparison logic — meaning AI visibility is not one-size-fits-all.
How Community Consensus Beats Brand Authority in AI Buying Advice
Across our analysis of ~1,000 high-intent BOFU prompts and 57,095 total citations, Reddit appears in roughly 62% of LLM responses, making it the most-cited domain in the dataset. YouTube appears in ~25% of responses, and G2 in ~5%. By comparison, Forbes appears in ~7%, CNBC in ~3%, and Business Insider in ~3%.
Grouped by domain type, community and review platforms collectively outweigh traditional editorial publishers. When users ask AI tools to compare products, pricing, or choose alternatives, models consistently pull from peer discussion and review ecosystems.
This pattern is strongest in prompts that require judgment — “X vs. Y,” alternatives, pricing comparisons, and “best for” queries. These questions force LLMs to weigh credibility signals and select supporting evidence.
In those moments, lived experience and community consensus appear more often than brand-owned pages or standalone publisher analysis.
For brands, that shifts emphasis toward visibility. Strong link building strategies support that ecosystem by earning placements on the same domains LLMs repeatedly cite.
The Comparison Economy — Why “X vs. Y” Content Wins AI Buying Decisions
Community platforms establish trust. Comparison pages structure the decision.
Across the 57,095 analyzed citations, comparison pages represent the largest share of cited URL types, followed by listicles such as “Best tools for X”. These formats dominate when users ask pricing, alternatives, and “which should I choose?” queries.
Most of these comparisons involve specific brand matchups rather than general product-type comparisons. In the prompt dataset, roughly one-third of queries explicitly asked for brand comparisons (e.g., “HubSpot vs. Salesforce,” “Asana vs. Monday,” or “Stripe vs. Square”), while the majority focused on “best X for Y,” pricing, or alternatives queries.
The URLs LLMs cite often mirror those brand comparison structures. Examples include side-by-side pages such as “HubSpot vs. Salesforce,” “Monday vs. Asana,” and “Shopify vs. WooCommerce,” which appear repeatedly across different prompts.
The same pattern appears at the individual URL level. Multiple entries in the top 10 most-cited URLs are explicit “X vs. Y,” alternatives, or pricing-comparison pages. These URLs recur across prompts even when the original query was broader, indicating that LLMs frequently rely on comparison pages as decision-stage evidence.
Comparison pages work well for LLMs because they already organize features, tradeoffs, and alternatives in a side-by-side format. That structure closely matches how decision-stage questions are asked, making it easier for models to reuse the information when generating recommendations.
Prompt structure likely contributes to this pattern as well. The dataset includes a mix of “best X for Y,” alternatives, pricing, and direct “X vs. Y” comparisons.
While many prompts explicitly asked for comparisons, the dominance of comparison URLs in citations suggests that even broader queries like “best CRM for startups” frequently resolve into comparison-style answers within LLM responses.
Product pages and brand homepages appear far less frequently in citations, despite being the most common content produced by brands. Their format centers on individual product narratives, while BOFU prompts require comparative reasoning.
For brands, this shifts emphasis toward comparison-led assets within a broader B2B content strategy, especially in competitive categories where buyers expect direct side-by-side evaluation.
Why Brand-Owned Content Rarely Shows Up in AI Buying Advice
Brand-owned domains appear infrequently in BOFU citations.
Most tracked brands sit in low single-digit citation visibility. AI-generated answers often mention brands by name, while third-party domains supply the supporting evidence.
Third-party sources account for the vast majority of BOFU citations. UGC platforms, review sites, affiliates, and publishers collectively represent approximately 80-95% of citations, depending on the industry. These domains provide the comparative framing and validation that LLMs reuse when constructing buying advice.
Some verticals show exceptions. In HR tech, for example, Gusto reaches ~9% visibility. These cases tend to involve strong third-party presence, clear comparison framing, and consistent visibility across trust-layer sources.
This shifts how teams measure content marketing ROI. The most influential moments often occur off-site, within the source LLMs referenced during evaluation.
Why AI Tools Recommend Different Sources
AI tools don’t pull from the same playbook.
Filtering the same BOFU prompts reveals consistent differences in citation mix across ChatGPT, Perplexity, Gemini, and Google AI Overview / AI Mode.
Google.com appears in roughly 10% of total citations, with usage concentrated heavily within Google AI experiences. That domain appears far less frequently in ChatGPT responses.
Perplexity surfaces a broader range of recently updated URLs, reflecting its emphasis on real-time retrieval. Its citation mix includes more live search results than other models in the dataset.
ChatGPT more consistently cites structured comparison pages and UGC-heavy domains, aligning with the broader pattern seen across BOFU prompts. As a result, models amplify different domains and formats.
These shifts affect which brands appear in recommendations and which content formats gain repeated visibility. Maintaining presence across AI-driven buying journeys requires understanding how each model sources and reuses information.
Why This Matters for AI-Driven Customer Acquisition
At the bottom of the funnel, AI tools influence which vendors buyers evaluate and compare. Our analysis shows that recommendations consistently draw from a concentrated set of third-party platforms and comparison pages.
That shift changes how visibility works. The domains LLMs cite most often help determine which products appear credible when buyers are making a decision.
Sourcing patterns also vary by model, making AI visibility a distributed ecosystem rather than a single ranking environment.
For growth teams, BOFU AI answers now operate as a revenue-stage channel. Visibility depends on presence across the third-party platforms and comparison ecosystems LLMs trust when constructing recommendations. This reality sits at the center of Generative Engine Optimization (GEO).
Siege Media helps brands audit and strengthen their AI source ecosystem through comparison-led content strategy, third-party authority-building, and full-source universe analysis.
Explore Siege Media’s GEO services to improve visibility inside AI-driven purchase decisions.
Methodology
This analysis draws on citation data from Peec AI, which tracks the sources large language models reference when generating answers to user queries. We analyzed approximately 1,000 bottom-of-funnel (BOFU) prompts reflecting commercial intent, including pricing, product comparisons, “best X for Y,” and alternatives searches.
The dataset includes 57,095 total citations across ChatGPT, Perplexity, Gemini, and Google AI Overview / AI Mode, collected between January 29 and February 4, 2026 (Peec.ai). Each citation represents a domain or URL explicitly used by an LLM in a BOFU response.
Sources were evaluated at both the domain and URL levels using Peec.ai’s classifications for domain type (e.g., UGC, editorial, corporate, reference) and content format (e.g., comparison, listicle, product page). Findings are based on citation frequency, not traffic or rankings.
Model-specific behavior was assessed by filtering the same prompt set by individual LLMs. Brand visibility was measured using Peec.ai’s brand metrics and cross-checked against domain-level citations to distinguish brand mentions from brand-owned sources.



